GPU 뭐 살까요?

한 줄 요약
Agent를 온프레미스에서 운영하려면, 메모리가 큰 GPU를 구매하세요.
들어가며
Agent를 직접 운영하려는 기업들과 이야기하다 보면 GPU에 대한 질문을 많이 받습니다. 클라우드 API를 쓰자니 비용이 걱정되고, 데이터를 외부로 보내기도 꺼려지는 곳들입니다. 그래서 직접 서버를 두고 운영해보자는 방향입니다. 가장 먼저 묻는 질문이 있습니다.
"최신 NVIDIA GPU 사면 되지 않나요?"
틀린 말은 아닙니다. 최신 GPU가 나쁠 리 없습니다. 예산이 충분하면 제일 좋은 것을 사면 됩니다. 그런데 현실은 그렇지 않습니다. 예산은 한정되어 있고, 그 안에서 선택을 해야 합니다.
저는 이 선택에서 많은 분들이 놓치는 게 있다고 봅니다. GPU를 고를 때 보통 연산 속도를 먼저 봅니다. 얼마나 빨리 계산하느냐. 스펙 시트에서 가장 눈에 띄는 숫자이기도 합니다.
그런데 Agent 운영에서는 연산 속도보다 메모리 크기가 더 중요한 경우가 많습니다. 왜 그런지 이야기해보려 합니다.
고지능 LLM들이 큰 메모리에 최적화 되어가고 있습니다.
LLM의 역사를 잠깐 돌아보겠습니다.
불과 몇 년 전만 해도 모델 구조는 단순했습니다. 파라미터가 많으면 똑똑하고, 적으면 덜 똑똑합니다. 70억 개짜리보다 700억 개짜리가 더 잘합니다. 그래서 더 큰 모델을 만들고, 더 큰 모델을 돌리려면 더 빠른 GPU가 필요했습니다. (ex. Meta의 Llama 초기 버전)
최근 발표되는 모델은 구조가 달라졌습니다. 쉽게 비유하자면 이렇습니다.
예전 모델은 "만능 직원 1명"이 회사를 운영하는 방식이었습니다. 어떤 질문이 들어오든 그 직원이 처음부터 끝까지 다 처리합니다. 회계 질문이 오면 회계를 하고, 마케팅 질문이 오면 마케팅을 합니다. 한 사람이 모든 걸 다 압니다. 단순합니다.
요즘 뜨는 모델은 다릅니다. "전문가 100명이 있는 회사"와 비슷합니다. 논리 전문가, 계산 전문가, 창의적인 업무 전문가가 각각 있습니다. 질문이 들어오면 그중 적합한 전문가 몇 명만 나서서 답합니다. 논리적인 질문이 오면 논리 전문가가 답하고, 나머지 99명은 가만히 있습니다.
효율적입니다. 매번 100명이 다 일하는 게 아니라 필요한 사람만 일하니까요. 문제는 여기서 생깁니다. 일하는 건 몇 명인데, 100명 전원이 사무실에 출근해 있어야 합니다.
생각해보면 당연합니다. 어떤 질문이 들어올지 모르니까요. 회계 질문이 올 수도 있고, 법률 질문이 올 수도 있습니다. 누가 필요할지 미리 알 수 없으니 일단 전원이 대기하고 있어야 합니다.
GPU 입장에서는, 계산은 몇 명분만 하더라도 100명이 앉아있을 자리는 있어야 한다는 뜻입니다. 연산 능력은 몇 명분만 있어도 되는데, 메모리는 100명분이 있어야 합니다. 연산은 빠른데 자리가 부족하면? 애초에 출근을 못 시킵니다. 모델을 아예 올릴 수가 없습니다. "메모리 부족"이라는 에러가 뜨면서 그냥 안 됩니다.
이런 구조를 MoE(Mixture of Experts)라고 부릅니다. 최근 떠오르고 있는 DeepSeek이나, 국가 파운데이션 모델들이 이 방식입니다. 그리고 이런 모델들이 점점 주류가 되고 있습니다. 효율이 좋으니까요. 같은 성능을 더 적은 연산으로 낼 수 있으니까요.
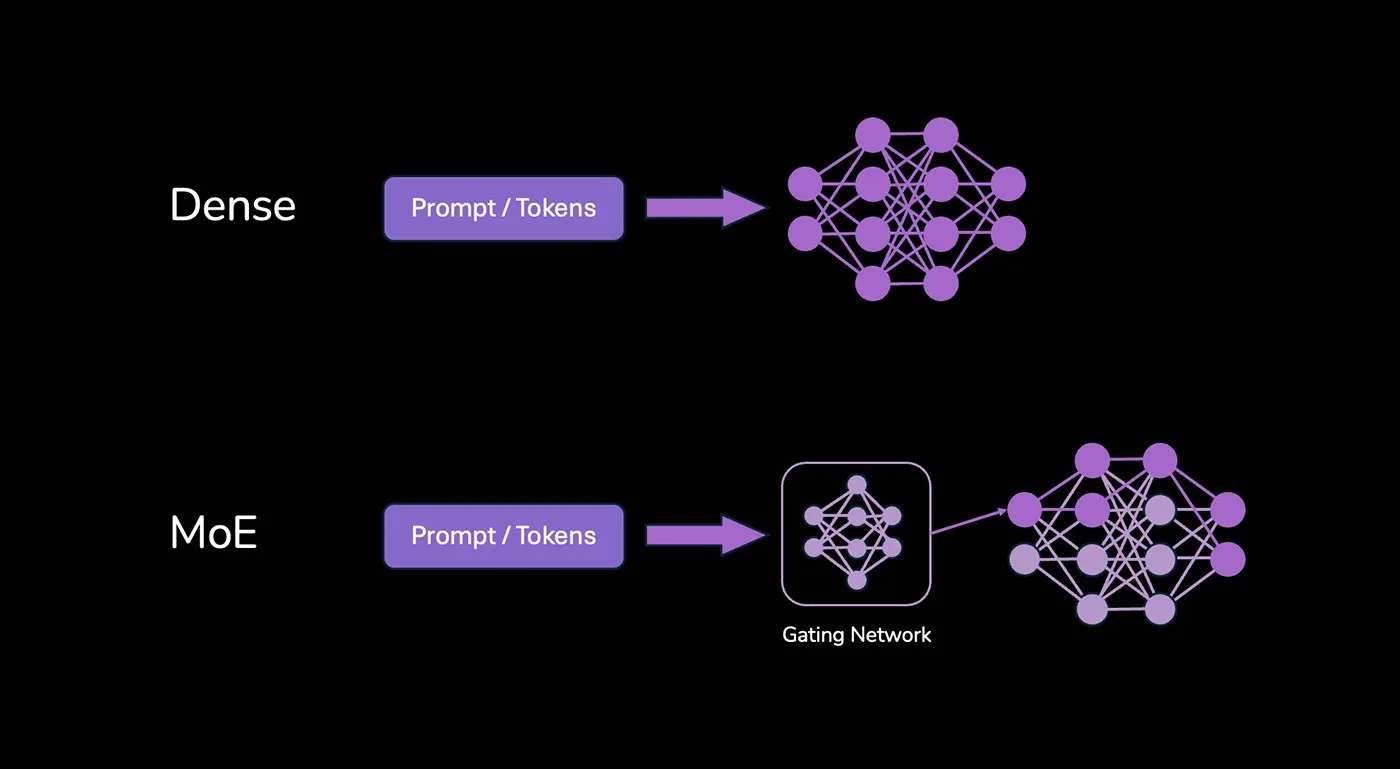
앞으로 Agent에 쓸 모델을 고른다면, 이런 구조의 모델을 쓸 확률이 높습니다. 그리고 이런 모델을 제대로 돌리려면 연산 성능보다 자리 수, 즉 메모리 크기가 먼저입니다.
Agent가 기억을 저장해야하기 때문입니다.
두 번째 이유는 Agent의 본질과 관련이 있습니다.
Agent가 일반 챗봇과 다른 점은 무엇일까요? 많은 사람들이 "도구를 쓸 수 있다"고 답합니다. 맞는 말입니다. 검색도 하고, API도 호출하고, 파일도 읽습니다. 그런데 저는 더 근본적인 차이가 있다고 봅니다.
Agent는 기억해야 합니다.
일반 챗봇은 질문하면 답하고 끝입니다. "오늘 날씨 어때?"라고 물으면 날씨 알려주고 끝납니다. 대화가 끝나면 잊어버려도 됩니다. 다음에 "어제 뭐 물어봤지?"라고 해도 모릅니다. 기억할 필요가 없으니까요.
Agent는 다릅니다. 이전에 뭘 이야기했는지 기억해야 합니다. "아까 말한 그 파일 다시 열어줘"라고 하면 아까 어떤 파일을 말했는지 알아야 합니다. 유저가 누구인지도 알아야 합니다. "내 프로젝트 현황 정리해줘"라고 하면 이 사람의 프로젝트가 뭔지 알아야 합니다.
지금 무슨 작업을 하고 있는지 맥락을 이어가야 합니다. "분석 다 됐으면 보고서로 만들어줘"라고 하면 방금 뭘 분석했는지 기억하고 있어야 합니다. 여러 도구를 호출하고, 그 결과를 조합해서 다음 행동을 결정해야 합니다. 이 모든 "기억"이 메모리를 차지합니다.
대화가 길어질수록, 참조할 정보가 많아질수록, 필요한 메모리가 늘어납니다. 한두 마디 주고받는 게 아니라 수십 번, 수백 번 대화가 오가면서 맥락이 쌓입니다. Agent가 호출한 도구의 결과도 기억해야 합니다. 검색 결과, API 응답, 파일 내용 전부 다요.
요즘 모델들을 보면, "128K 토큰 지원", "200K 토큰 지원"이라는 내용이 함께 등장합니다. 아주 긴 대화도 기억할 수 있다는 뜻입니다. 책 한 권 분량을 통째로 기억하면서 대화할 수 있다고 합니다. 너무 멋지지만, 온프레미스에서 구현하려면 그만큼의 메모리가 필요합니다.
비유하자면 이렇습니다. 기억력 좋은 비서를 쓰려면 그 비서가 메모를 쌓아둘 책상이 커야 합니다. 아무리 머리가 좋아도 메모할 곳이 없으면 기억을 못 합니다. 연산이 빠른 건 의미 없습니다. 기억을 쌓아둘 공간이 있어야 합니다.
Agent를 제대로 운영하고, 긴 맥락을 유지하면서 일하게 하려면, 메모리가 충분해야 합니다.
텍스트를 넘어서면 용량이 폭발합니다.
세 번째 이유는 미래와 관련이 있습니다.
지금 대부분의 Agent는 텍스트 중심입니다. 텍스트로 질문하고, 텍스트로 답합니다. 문서를 읽고, 문서를 씁니다. 그런데 앞으로도 그럴까요?
이미지도 보고, 음성도 듣고, 영상도 분석하는 Agent가 점점 늘어날 것입니다. 사실 이미 늘어나고 있습니다. GPT-4o나 Gemini 같은 모델들은 처음부터 여러 형태의 데이터를 다루도록 만들어졌습니다. 텍스트만 다루는 모델은 점점 구식이 되어가고 있습니다. "이 이미지에서 표 추출해줘", "이 영상 요약해줘", "이 음성 파일 텍스트로 바꿔줘". 이런 요청을 처리하는 Agent가 점점 많아질 것입니다. 그게 더 쓸모 있으니까요.
문제는 데이터 크기 차이입니다.
텍스트는 가볍습니다. 아주 긴 문서라도 별로 무겁지 않습니다. 소설 한 권이 수십만 글자인데, 컴퓨터 입장에서는 아무것도 아닙니다. 그런데 이미지 한 장은 텍스트의 수십 배 무게입니다. 고화질 이미지 하나가 문서 수백 장 분량을 차지합니다. 영상은 말할 것도 없습니다. 영상은 초당 수십 장의 이미지가 연속으로 이어진 모음입니다. 1분짜리 영상이면 이미지가 수천 장입니다. 각각이 다 메모리를 차지합니다.
물론 이걸 효율적으로 처리하는 기술들이 있습니다. 압축도 하고, 샘플링도 합니다. 그래도 텍스트와는 차원이 다릅니다. 텍스트만 다룰 때 충분하던 메모리가, 이미지 몇 장 들어오면 순식간에 바닥납니다. 멀티모달 Agent를 생각한다면, 메모리는 "크면 좋다"가 아니라 "커야만 한다"에 가깝습니다.
지금 당장은 텍스트만 다룰 계획이라도, 나중에 확장할 가능성을 생각하면 메모리는 넉넉할수록 좋습니다.
그래서 어떻게 해야 할까요
정리하면 이렇습니다.
예산 제약이 있다면, 일단 메모리 큰 GPU 하나로 시작해보시길 권장합니다. 당장 운영에서 트래픽을 다 받아내지 못하더라도 괜찮습니다. 모델 학습이나 파인튜닝 용도로 활용할 수 있습니다. 메모리 큰 GPU는 어디든 쓸 데가 있습니다.
예산을 유연하게 쓸 수 있다면 가장 좋습니다. 메모리 큰 GPU 하나로 학습과 운영을 같이 돌려보고, 트래픽을 보면서 필요할 때 늘려가면 됩니다. 처음부터 크게 가는 것보다 작게 시작해서 키우는 게 리스크가 적습니다.
- LLM의 구조가 바뀌고 있습니다. 전문가 여러 명이 나눠서 일하는 방식이 대세가 되고 있는데, 이 방식은 모든 전문가가 메모리에 올라가야 합니다. 일하는 건 일부지만, 전원이 출근해 있어야 합니다.
- Agent는 긴 맥락을 기억해야 합니다. 단발성 챗봇이 아니라 대화를 이어가고, 도구를 쓰고, 결과를 조합해야 합니다. 기억이 길수록 메모리를 많이 씁니다.
- 멀티모달로 가면 메모리 사용량이 폭발합니다. 텍스트는 가볍지만, 이미지와 영상은 무겁습니다. 무거운 데이터를 올릴 수 있는 큰 메모리가 필요합니다.
세 가지 모두 같은 방향을 가리킵니다. 메모리가 중요합니다.
Agent는 유망한 기술입니다. 실제로 사람의 일을 자동화할 수 있습니다. 이미 그렇게 쓰이고 있고, 앞으로 더 많이 쓰일 겁니다. 다만, 온프레미스 환경에서 운영하는 것은 쉽지 않습니다. 클라우드 API를 쓰는 것과는 고민의 결이 다릅니다. 직접 서버를 두고 모델을 올리고 운영하려면 신경 쓸 게 많습니다.
그중에서도 GPU 선택은 첫 번째 관문입니다. 그리고 이 관문에서 많은 분들이 잘못된 질문을 합니다. "얼마나 빠른가"를 먼저 묻습니다.
가장 첫 번째 중요한 질문은 "얼마나 담을 수 있는가"입니다.